Education
Experience
- Verilog / SystemVerilog
- Python
- C++
- JavaScript
- MATLAB
- Cadence Virtuoso
- Synopsys DC / PrimeTime
- Xilinx Vivado / Quartus
- ModelSim / XSim / Verilator
- Altium Designer
- 65nm TSMC CMOS
- FPGA & ASIC Design
- Digital & Analog Design
- RTL Verification
- SPICE / COMSOL
- LLM / Transformer RTL
- FPGA AI Acceleration
- Intel AI Tensor Blocks
- Electro-Optical Systems
- Linux / Git
5-Stage Pipelined RISC-V CPU
A fully functional 5-stage pipelined processor implementing the RISC-V ISA, written in Verilog. Supports the RV32I base integer instruction set with full pipeline hazard handling.
Designed for correctness and performance: data hazards are resolved via forwarding paths from EX and MEM stages, minimizing pipeline stalls. Control hazards use branch prediction with flush logic.
- IF → ID → EX → MEM → WB pipeline with full data forwarding
- Hazard detection unit with stall and flush control
- Register file with dual async read, synchronous write
- ALU supporting R-type, I-type, S-type, B-type, U-type, J-type
- Simulated and verified in ModelSim / On Board Testing
// Hazard detection + forwarding unit module hazard_unit ( input [4:0] ID_EX_Rs1, ID_EX_Rs2, input [4:0] EX_MEM_Rd, MEM_WB_Rd, input EX_MEM_RegWrite, MEM_WB_RegWrite, input ID_EX_MemRead, output reg [1:0] ForwardA, ForwardB, output reg Stall ); // Load-use hazard: stall one cycle always @(*) begin Stall = ID_EX_MemRead && ((ID_EX_Rs1 == EX_MEM_Rd) || (ID_EX_Rs2 == EX_MEM_Rd)); // EX forwarding: most recent result ForwardA = (EX_MEM_RegWrite && EX_MEM_Rd == ID_EX_Rs1) ? 2'b10 : (MEM_WB_RegWrite && MEM_WB_Rd == ID_EX_Rs1) ? 2'b01 : 2'b00; ForwardB = (EX_MEM_RegWrite && EX_MEM_Rd == ID_EX_Rs2) ? 2'b10 : (MEM_WB_RegWrite && MEM_WB_Rd == ID_EX_Rs2) ? 2'b01 : 2'b00; end endmodule
iBERT LLM Inference Pipeline
A hardware-accelerated inference pipeline for BERT-based language models, implemented in SystemVerilog. Designed to execute transformer attention blocks and feed-forward layers with minimal latency.
iBERT leverages integer-only arithmetic throughout the pipeline, eliminating floating-point operations from the critical path. Attention score computation, softmax approximation, and matrix multiplications are all mapped to fixed-point integer datapaths.
- Integer-only attention and computation blocks (iBERT quantization)
- Systolic array structure for matrix multiply acceleration
- Layer normalization approximation in integer arithmetic
- Parallelised multi-head attention processing
- End-to-end pipeline functional on Pynq FPGA
// Integer attention score computation — QK^T / sqrt(d_k) module int_attention_core #( parameter D_K = 64, parameter SEQ = 128 )( input logic clk, rst_n, input logic signed [7:0] Q [0:SEQ-1][0:D_K-1], input logic signed [7:0] K [0:SEQ-1][0:D_K-1], output logic signed [15:0] scores [0:SEQ-1][0:SEQ-1] ); logic signed [15:0] acc; integer i, j, k; always_ff @(posedge clk) begin for (i=0; i<SEQ; i++) for (j=0; j<SEQ; j++) begin acc = 0; for (k=0; k<D_K; k++) acc += Q[i][k] * K[j][k]; // INT8 dot product scores[i][j] <= acc >>> 3; // approx /sqrt(64) via right-shift end end endmodule
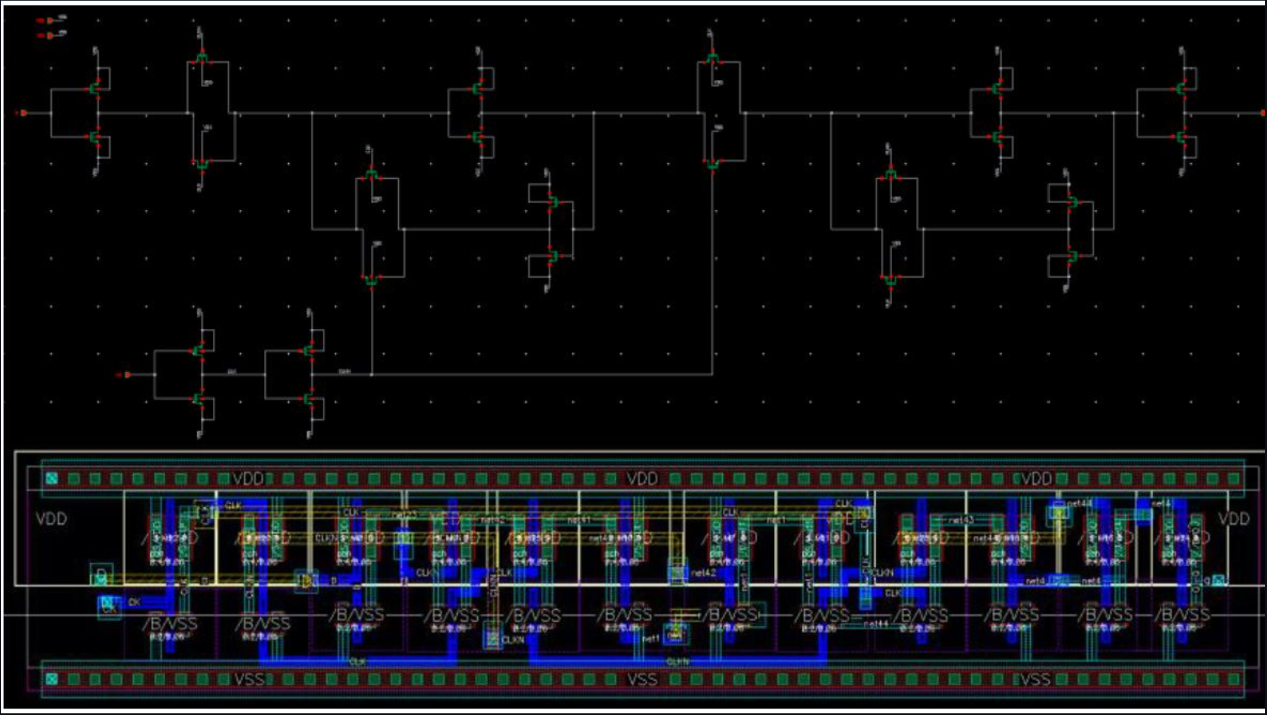
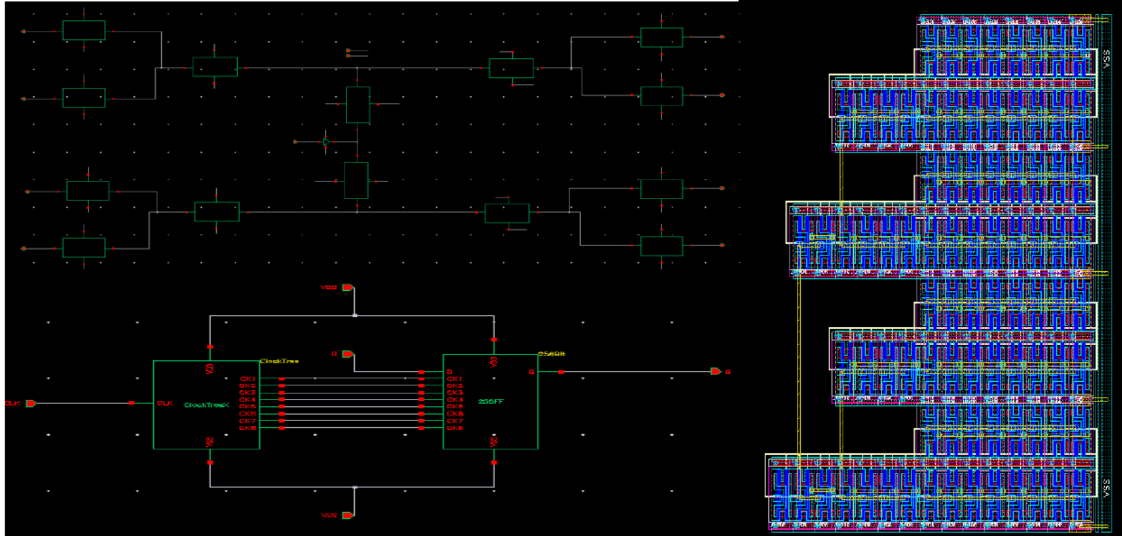
256-Bit Scan Chain
A 256-bit serial scan chain implemented and laid out in Cadence Virtuoso, designed as a Design-for-Test (DFT) structure to enable full controllability and observability of internal flip-flop states.
Each scan flip-flop is a modified D-FF with an additional scan input and a mode-select mux. In scan mode, all 256 FFs form a serial shift register, allowing test vectors to be shifted in and captured results shifted out.
- 256 scan-enabled D flip-flops in series
- Designed, simulated, and laid out in Cadence Virtuoso
- DRC and LVS clean layout with full connectivity verification
- Mode-select logic: functional mode vs. scan shift mode
- Supports shift-in, capture, and shift-out test sequences
0
1
2
254
255
Normal FF operation
Serial shift register
// Scan-enabled D flip-flop — core cell of the 256-bit chain module scan_dff ( input wire clk, // clock input wire scan_en, // 1 = scan mode, 0 = functional input wire d, // functional data input input wire si, // scan input (from prev FF) output reg q, // FF output output wire so // scan output (feeds next FF) ); wire d_mux = scan_en ? si : d; // select input based on mode always @(posedge clk) q <= d_mux; assign so = q; // pass Q to next cell in chain endmodule // Instantiation across 256 cells genvar i; generate for (i = 0; i < 256; i++) scan_dff ff_inst (clk, scan_en, d_in[i], i == 0 ? SI : chain_q[i-1], // SI chaining chain_q[i], chain_so[i]); endgenerate
OpenVLA FPGA Acceleration
Accelerating the Meta OpenVLA vision-language-action model by mapping transformer MLP layers onto an Intel Agilex-5 FPGA using SystemVerilog, Quartus Prime, and Intel's FPGA AI Suite with AI Tensor blocks.
Characterised matrix dimensions, precision requirements, and data reuse patterns of each transformer layer to guide FPGA mapping and accelerator architecture decisions. Targeting 10% lower power and 5% higher throughput versus CPU baselines.
- Intel Agilex-5 FPGA target — AI Tensor block utilisation
- Transformer MLP layer mapping: dimension analysis and dataflow optimisation
- Mixed-precision strategy per layer to balance accuracy and resource usage
- Quartus Prime + Intel FPGA AI Suite for synthesis and placement
- Target: −10% power, +5% throughput vs CPU baseline
// MLP layer accelerator for OpenVLA on Intel Agilex-5 // Maps transformer feed-forward blocks onto AI Tensor blocks module mlp_accelerator #( parameter D_MODEL = 4096, parameter D_FF = 11008, // LLaMA-style FFN hidden dim parameter PREC = 8 // INT8 weights )( input logic clk, rst_n, valid_in, input logic signed [PREC-1:0] x [0:D_MODEL-1], input logic signed [PREC-1:0] W1 [0:D_FF-1][0:D_MODEL-1], output logic signed [15:0] out [0:D_FF-1], output logic valid_out ); // Systolic tile — maps to Agilex-5 AI Tensor block primitive genvar i; generate for (i = 0; i < D_FF; i++) dot_product_unit #(D_MODEL, PREC) dp ( clk, valid_in, x, W1[i], out[i], valid_out ); endgenerate endmodule